
分散アーキテクチャでは、メッセージ配信(イベント配信)の信頼性についての理解が必要になります。
一見、分散処理を実装していないから関係ないや、と思うかもしれませんが、
身近なところで、高度な分散アーキテクチャが使われています。
それは、クラウドサービスのマネージドサービスです。
なかでも、僕もいつも利用させていただいているAWSについて取り上げます!
この「メッセージ配信の信頼性」。僕もAWS初心者の頃、ハマりました。
メッセージ配信の信頼性
まず、メッセージ配信の信頼性を表す分類として、一般的に以下の3種類があります。
- at most once:最高1回配信
→ 欠損するかもしれないが、重複することはない - at least once:最低1回配信
→ 重複するかもしれないが、欠損することはない - exactly once:確実に1回配信
→ 重複も欠損もしない
マネージドサービスを利用する場合に、利用しようとしているサービスが、
「at most once」なのか「at least once」なのか「exactly once」なのか確認してから設計するようにしないと、
思いもよらない障害を発生させてしまうことになります。
“思いもよらない”と書いているのは、重複や欠損はそう簡単には発生しないため、結構な処理量が無いと障害が発生しないケースが多々あるためです。
実装時の動作確認や単体・E2Eテストでは発生しにくいですし、負荷テストで発覚すれば良いですが、
そうでない場合は本番稼働後に障害が発生して気づくことになります。
例えば、ECサイトにおいて注文処理後の決済処理をメッセージキューを中継して処理する場合に、メッセージキューが「at least once」ということに知らずに設計/実装してしまうと、運悪くエラーにもならずに処理できてしまった場合に、2重で決済処理が行われてしまい、2重で請求されてしまう。ということにもなりかねません。
間違った設計や実装をしてしまわないためには、自分自身が知識を身につけることが重要になってきます。
また、設計レビューやコードレビューを行い開発チーム全体の品質を上げることも重要です。
AWSにおける欠損や重複
いくつか利用する頻度の高いマネージドサービスを中心に、注意が必要な箇所をピックアップします。
AWSのマネージドサービスでは、「at least once」であることが多いです。
S3(イベント通知)
技術ブログやQiitaなんかを眺めていると、
S3のイベント通知をトリガーに処理を実行する方法が沢山載っているのですが、肝心なことが書かれていない。
それは、
- イベント通知が遅延することがある
- イベント通知が重複して配信されることがある
- イベント通知が配信されないことがある
ということ。
AWSの公式にはきちんと書かれています。
Amazon S3 イベント通知は、少なくとも 1 回配信されるように設計されています。通常、イベント通知は数秒で配信されますが、1 分以上かかる場合もあります。
バージョン管理されていない単一のオブジェクトに同時に 2 つの書き込みを行うと、イベント通知が 1 つしか送信されない場合があります。バケットのバージョニングを有効にすると、正常な書き込みごとにイベント通知を受信できます。バージョニングでは、正常な書き込みごとにオブジェクトの新しいバージョンが作成され、イベント通知が送信されます。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/NotificationHowTo.html
S3のイベント通知は1分以上かかる場合があり、
同じパスへの同時書き込みではイベント通知が欠損する可能性があります。
したがって、1分以上の遅延が許されない場合や、
S3の同じパスへの書き込みが発生するケースで、書き込んだ回数だけ処理を実行したい場合には、
S3のイベント通知は使わないほうが良いです。
では、どのような構成が望ましいかというと、
- S3にファイルアップロードするときやファイルを削除するときに、
SQSにS3のパスを含んだメッセージを登録 - SQSのメッセージをトリガーに処理を実行する。
などが考えられます。
SQS(標準キュー)
標準キューを使用している場合は「at least once」となり、重複が発生する可能性があります。
Amazon SQS では、冗長性と高可用性を確保するため、メッセージのコピーが複数のサーバーに保存されます。まれではありますが、メッセージを受信または削除するときに、メッセージのコピーが保存されているサーバーの 1 台が使用できない場合があります。
この場合、使用できないサーバーではメッセージのコピーが削除されず、メッセージの受信時に、そのメッセージコピーをもう一度受け取る場合があります。アプリケーションがべき等になるよう設計する必要があります (同じメッセージを繰り返し処理した場合にも悪影響が発生しないように設計する必要があります)。
https://docs.aws.amazon.com/ja_jp/AWSSimpleQueueService/latest/SQSDeveloperGuide/standard-queues.html
SQSの標準キューを利用する場合は、
キューのメッセージを受信して処理する側で、冪等処理になるように設計・実装する必要があります。
ちなみに、FIFOキューは「exactly once」を保証しています。
標準キューとは異なり、FIFO キューでは重複メッセージがありません。FIFO キューは、重複をキューに送信することを防止するのに役立ちます。5 分間の重複排除間隔内に
https://docs.aws.amazon.com/ja_jp/AWSSimpleQueueService/latest/SQSDeveloperGuide/FIFO-queues.html#FIFO-queues-exactly-once-processingSendMessageアクションを再試行しても、Amazon SQS ではキューに重複を挿入しません。
CloudWatch Events
まれに、単一のイベントまたはスケジュールされた期間に対して同じルールを複数回トリガーしたり、特定のトリガーされたルールに対して同じターゲットを複数回起動したりする場合があります。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/events/CWE_Troubleshooting.html#RuleTriggeredMoreThanOnce
CloudWatch Eventsは「at least once」です。
定期処理のトリガーとしてCloudWatch Eventsを利用していると、稀にタスクが2つ起動することがあるようです。
Lambdaを起動する場合でも同様で、Lambdaの同時実行数を1にしてもダメ。1つのLambdaが起動して処理が終了した後にもう1つのLambdaが起動する可能性があるため。
Lambda(非同期)
Lambdaの起動方法として同期、非同期、ストリームの全部で3種類あります。
このうち、非同期でLambdaを呼び出す場合には、
Lambdaの内部でイベントがキューイングされたのち、Lambdaが起動します。
したがって、SQSの通常キューと同様に、非同期でLambdaを呼び出す場合、重複が発生する可能性があります。
- 同期
-
- Application Load Balancer(ALB)
- API Gateway(非同期呼び出しにもできる)
- Cognito
- Alexa
- Lex
など
- 非同期(Event型)
-
- SQS
- SNS
- SES
- S3
- AWS IoT
- KinesisFirehose
- CloudWatch Events
- CloudWatch Logs
など
- ストリーム型
-
- DynamoDB
- Kinesis Stream
など
(注意)SQS(FIFOキュー)とLambdaの組み合わせ
先ほどSQS(FIFOキュー)自体は、「exactly once」を保証していると書きましたが、
FIFOキューをトリガーにLambdaを実行する場合は「at least once」となり、重複が発生する可能性があると、AWSの公式ブログに記載されています。
Amazon SQS FIFO queues ensure that the order of processing follows the message order within a message group. However, it does not guarantee only once delivery when used as a Lambda trigger. If only once delivery is important in your serverless application, it’s recommended to make your function idempotent. You could achieve this by tracking a unique attribute of the message using a scalable, low-latency control database like Amazon DynamoDB.
https://aws.amazon.com/jp/blogs/compute/new-for-aws-lambda-sqs-fifo-as-an-event-source/
リトライを考えると冪等であるべき
非同期呼び出しやストリーム型の呼び出しでは、呼び出し元の設定で自動リトライ設定をする設定にしていることが多いと思います。あるいは、自動リトライする設定から変更することができない。
自動リトライする設定の場合、Lambdaが異常終了したときに決められた回数分だけリトライされることで、異常終了が発生するまでのコードが繰り返し実行されてしまいます。
したがって、自動リトライする設定の場合は、Lambdaが重複起動しなくとも、そもそも冪等であるべきです。
(同じことがLambda以外にも言えます)
at least once とうまく付き合う
多重実行を許容する
処理の重複(多重実行)が発生を許容できるのであれば、なにもしなくて良い。
「ただデータを取得するだけの処理」など。
多重実行を許容しない
重複を許容しないのであれば、冪等になるように設計、実装する。
紹介するのは、以下のスライド(p.59)に記載されているDynamoDBを用いて冪等性を担保する方法
冪等性はお客様のコードで確保する必要がある
⎻ AWS Lambdaで保証しているのは最低1回実⾏することであり1回しか実⾏しないことではない
⎻ 同⼀イベントで同⼀Lambdaファンクションが2回起動されることがまれに発⽣する
⎻ DynamoDBを利⽤するなどして冪等性を担保する実装を⾏うこと
https://www.slideshare.net/keisuke69/serverless-antipatterns/59/
次の図は、SQS(標準キュー)からLambdaがメッセージを受信して、ある多重実行が許されない処理を行う例です。
この時にDynamoDBを利用すると比較的簡単に冪等処理にできます。
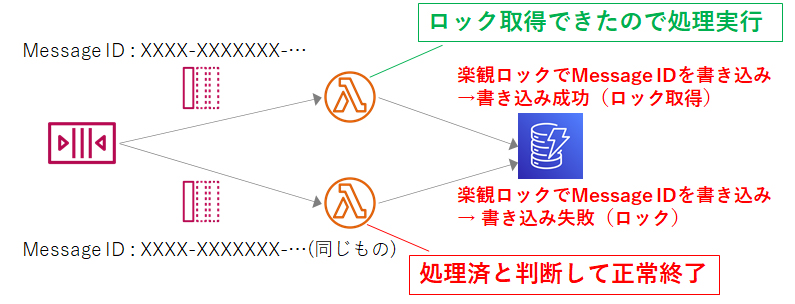
- SQSから同じメッセージをLambda AとLambda Bで受信する。
- 先にSQSからメッセージを受信したLambda Aは、受信したメッセージのMessage IDと同じMessage IDがDynamoDBのテーブルに書き込まれていないことを確認した上でMessage IDを書き込む(→ロック取得)
- Lambda Aで処理を実行
- 後からSQSからメッセージを受信したLambda Bは、同じく受信したメッセージのMessage IDと同じMessage IDが既にDynamoDBのテーブルに書き込まれており(Lambda Aが書き込んでいるので)、処理済と判断して何もせずに正常終了
※書き込んだMessage IDはDynamoDBのTTL設定(生存時間設定)で3日後とかにテキトーに消す。
まとめ
AWSのマネージドサービスが高可用性、耐障害性を保証している背景には、高度な分散処理の世界があって、便利な面だけをみて設計すると失敗する良い例かと思い、取り上げてみました。
仕様のみをみて書いている箇所もあるので、今度は実際にどのくらいの頻度で重複が発生するのか、確認したいところです。
